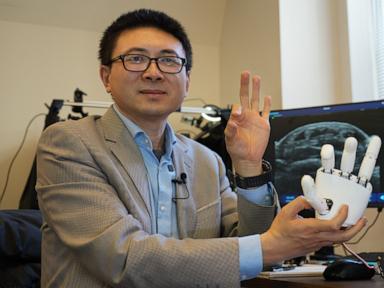
Robotics has a dirty secret that few labs want to talk about. Training a robot to do even the simplest task—like picking up a mug or wiping a counter—requires an agonizingly slow, manual process. Engineers spend weeks guiding mechanical arms through repetitions or donning bulky, thousand-dollar virtual reality suits to record "demonstrations." This data bottleneck has stalled the deployment of automation in homes and factories for a generation.
MIT researchers may have just broken this logjam by developing a system that converts simple hand gestures, filmed on an ordinary camera, into clean robot training data.
By eliminating the need for specialized hardware and tedious manual programming, the new framework democratizes how machines learn. It allows non-experts to instruct hardware using intuitive movements. However, this breakthrough introduces a messy new set of challenges regarding data precision, edge-case failures, and the unpredictable physics of the real world.
The Training Bottleneck That Stalls Automation
Industrial robots are brilliant at repetition but utterly helpless when confronted with novelty. To make a robot adaptable, engineers rely on imitation learning. The machine watches a human perform a task and tries to copy the underlying logic.
Historically, collecting this behavioral data has been a nightmare. Engineers typically use two primary methods, both of which are deeply flawed.
- Teleoperation: A human operator uses a joystick or a digital twin to steer the robot manually. It is exhausting, slow, and requires technical training.
- Exosuits and VR: Operators wear specialized gloves or motion-tracking gear. While effective, these systems cost tens of thousands of dollars and calibrate poorly across different human body types.
Because of these hurdles, a typical robotics dataset might consist of a few hundred demonstrations collected over months. For context, modern AI vision systems require millions of images to understand the difference between a cat and a dog. Robotics has been starving for data. The MIT approach aims to turn the billions of hours of human hand movements already captured on video into a vast, searchable library of machine instructions.
Translating Human Hands into Mechanical Joints
The core problem with watching a human hand on video is anatomical mismatch. A human hand has 27 degrees of freedom, driven by a complex web of muscles and tendons. A standard industrial robot arm might have six or seven joints, ending in a rigid two-pronged gripper.
If a robot tries to copy human finger placement directly, it fails. The geometry is wrong.
[Human Hand: 27 Degrees of Freedom]
│
▼ (The Translation Gap)
│
[Robot Gripper: 2-7 Degrees of Freedom]
The MIT system bridges this gap through a two-step translation process that focuses on intent rather than exact replication.
Mapping Keypoints
First, a standard camera tracks the human hand, identifying key joints and the relationships between them. It ignores the skin texture, the background, and the specific size of the operator's hand. The system distills the movement down to a mathematical skeleton.
Retargeting Optimization
Second, the software runs an optimization algorithm that asks a fundamental question: Given the physical limitations of this specific robot arm, what movement best achieves the same spatial goal as the human hand? If the human closes their thumb and forefinger, the algorithm translates that to the closure of a mechanical claw, adjusting for the robot’s torque limits and reach.
This happens in real time. A user can stand in front of a webcam, mimic the act of opening a jar, and the system translates that gesture into a trajectory that a robot can execute immediately.
The Illusion of Simplicity
It sounds flawless on paper. In practice, stripping away the specialized hardware introduces a massive blind spot: the loss of haptic feedback.
When a human operator wears a high-end data glove or uses a physical joystick to guide a robot, they feel resistance. They know exactly how hard the robot is pressing against a surface. They can feel when a screw is stripped or when a cardboard box is about to crush under too much pressure.
A webcam cannot feel.
By relying entirely on vision, the MIT framework forces the AI to guess the forces involved in an interaction. If an operator moves their hand quickly to pick up an egg, the system sees the trajectory but misses the delicate pressure modulation required to keep the egg intact.
"Vision tells you where the object is, but touch tells you how to interact with it. Replacing touch with visual estimation is the greatest gamble of this new approach."
Furthermore, video data is notoriously noisy. Shadows, shifting light conditions, and self-occlusion—where the back of the hand blocks the camera's view of the fingers—can cause the tracking software to glitch. In a factory setting, a single dropped frame or misinterpreted gesture could result in a mechanical collision, damaging expensive hardware or injuring nearby workers.
The Economic Ripple Effects
If the research team can stabilize these edge cases, the economic implications for manufacturing and logistics are staggering.
Right now, small and medium-sized enterprises are priced out of advanced robotics. They cannot afford the systems integrators required to program robots for short-run manufacturing jobs. If a factory needs to change its assembly line every three weeks to produce different products, traditional robot programming is a financial non-starter.
+------------------------------------+------------------------------------+
| Traditional Programming | Gesture-Based Learning |
+------------------------------------+------------------------------------+
| Requires specialized consultants | Operated by existing floor staff |
| Weeks of downtime for calibration | Hours of video demonstration |
| High capital expense (VR/Pendants) | Low capital expense (Standard CAM) |
+------------------------------------+------------------------------------+
By shifting the training mechanism to simple video demonstration, a line worker can show a camera how to pack a new type of box in ten minutes. The robot processes the data, runs the optimization loop, and begins working the same afternoon. This shifts robotics from a capital-intensive software problem to an operational training problem.
Scaling Past the Lab
The true test of this technology will not happen in a pristine Cambridge laboratory. It will happen in chaotic, dusty, real-world environments.
For gesture-to-data pipelines to succeed globally, the underlying AI models must become resilient to environmental variance. The system needs to understand that a hand gesture performed in a dimly lit warehouse by a worker wearing heavy work gloves means the exact same thing as a gesture performed by a bare-handed researcher under studio lighting.
Moreover, the robotics industry must align on standardization. If every robot manufacturer maintains a proprietary control architecture, the translation layer must be rewritten for every single machine variant on the market. Universal translation requires universal compatibility.
The work coming out of MIT proves that the data bottleneck is not an permanent law of physics; it is an engineering hurdle that can be bypassed with clever software. The future of automation belongs to machines that can watch us, understand our intent, and adapt to our world without requiring us to learn their language.



